Modern data pipeline orchestration
Achieve enterprise data workflow orchestration and build a reusable data automation framework to boost efficiency and enable data-driven decision-making.

Create clarity from chaos
Build and scale your automations without adding complexity using a platform and orchestration architecture made for the modern data stack.
-

Adaptive data flows
Create workflows that adapt and respond to the status of your data pipelines with powerful design and monitoring capabilities. -

Total visibility
Keep an eye on the entire data lifecycle, from collection to analysis and downstream tasks across any technology from a single view. -

Composable automation
Architect data pipelines using a common set of reusable data management automation components and configurations. -

Hybrid-ready design
Available as SaaS or self-hosted, RunMyJobs by Redwood enables you to rapidly scale and innovate your data integration, transformation and more.
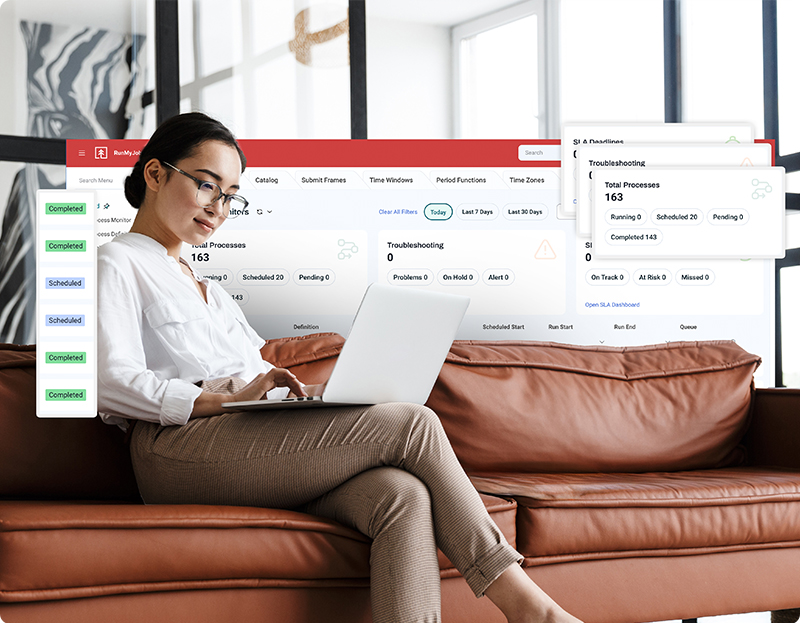
Stay proactive with flexible workflow tools
To maintain intact data pipelines with high job throughput, you need data orchestration tools that offer rule-based scheduling and dynamic workload balancing. With RunMyJobs, you get both, plus real-time monitoring and alerting via convenient dashboard views. These controls allow you to align your automated workflows with IT service management and meet defined SLAs.
Machine learning capabilities offer predictive analytics to help your data team stay proactive and prevent interruptions.
Customize the platform by extending its UI or workflow logic by leveraging low-code or developer options.

Integrate with your data infrastructure
Establish your ecosystem your way using hundreds of built-in integrations or the RunMyJobs connector catalog to extend your data engineering capabilities with servers, cloud apps, business services and mainframes. Integrate seamlessly with Databricks, Snowflake, Microsoft SQL Server and more. New connectors and templates are added to the catalog regularly, so you get immediate access to the latest integrations and updates.
Build your own integrations in minutes with the Connector Wizard, or use SOAP and REST APIs to connect to inbound, outbound and asynchronous web services.
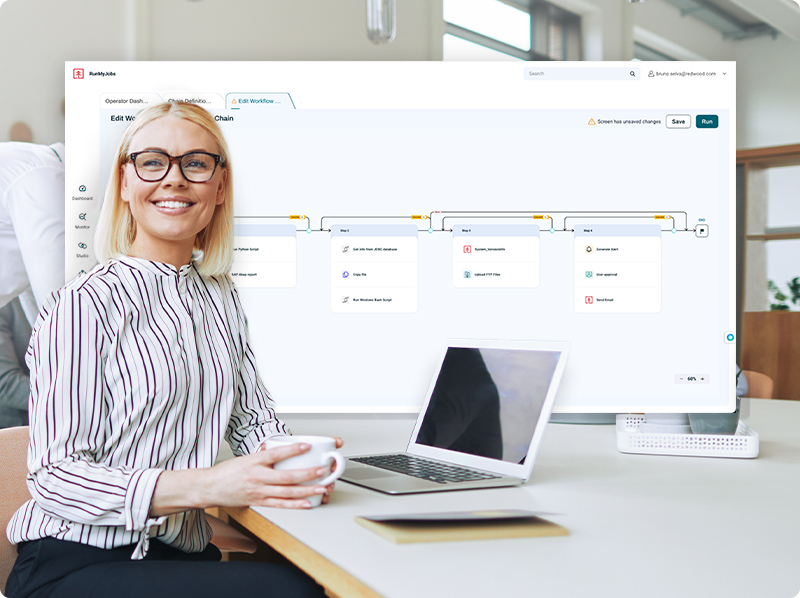
Maintain data quality despite complexity
The volume and types of data processed by the average enterprise today paint a complex picture, but how you manage that data doesn’t have to be equally complex.
With RunMyJobs’ workflow object model, you can create workflows in a drag-and-drop visual interface using sequential and parallel processing, exception management and process nesting with file, job and script parameter mapping.
Build scalable automations with scripting and application templates and create job blueprints and reusable components across workflow configurations. Set up rules for when and in what circumstances a workflow or job can start to control execution and align with other processes.

Choose on-premises, cloud-based or hybrid
Available as SaaS or self-hosted, RunMyJobs scales across services and applications without agents, creating a lightweight and flexible deployment.
Rely on secure and cloud-ready communication for all channels using TLS encryption to connect to applications and services directly, hosting the secure gateway in your chosen environment. Redwood Software has extensive security certifications, including ISO 27001, ISAE 3402 Type II, SSAE 18 SOC 1 Type II and SOC 2 Type II.
Incur lower overhead and enjoy more flexibility with no server agents for application connections. Deploy a featherweight agen

Autonomous execution of data movement tasks for SAP
RunMyJobs is SAP’s #1 job scheduler, enabling autonomous integration for SAP customers by orchestrating complex, end-to-end processes across SAP and non-SAP systems. It ensures efficient, consistent and accurate data flows to and from SAP BTP data management tools, including SAP Datasphere and SAP Analytics Cloud.
Related resources
Dive deeper into the problems RunMyJobs solves for modern data orchestration use cases.



Data pipeline orchestration FAQs
What is data pipeline orchestration?
Data pipeline orchestration is the automated coordination and management of data processes and workflows across multiple systems, applications or environments. It involves scheduling, monitoring and ensuring that data flows seamlessly between different pipeline stages, from extraction to transformation to loading into a target system, such as a data lake or data warehouse.
Orchestration tools, such as Apache Airflow, Dagster or advanced workload automation tools like RunMyJobs by Redwood, automate tasks like triggering data workflows based on specific events or schedules, handling dependencies between tasks, managing failures and optimizing compute resources. These workflows, often represented as directed acyclic graphs (DAGs), ensure that the right data is processed in the correct order.
Orchestration enables modern, data-driven businesses to integrate data from data sources and handle big data pipelines efficiently.
Discover the six benefits of automating data pipelines.
What is the difference between ETL and orchestration?
Extract, transform, load (ETL) and orchestration are related but distinct processes in data management. ETL is a process specifically designed to extract data from various sources, transform it into a suitable format using tools or languages like Python and load it into a target system, such as a data warehouse. It’s focused on the movement and transformation of data. It’s focused on the movement and transformation of datasets.
Orchestration is broader and involves managing and automating the entire workflow of data processes, including ETL and other operations like data governance, data validation, DataOps and integration with external tools and task sequencing. While ETL handles data manipulation, orchestration ensures that ETL jobs and other processes are executed in the correct order, handle dependencies and respond to failures or changes in real time, keeping the overall pipeline running smoothly.
Learn more about the ETL automation process and how choosing the right solution lets you extend workflow orchestration.
What is data orchestration?
Data orchestration is the process of automating and coordinating the flow of data across multiple systems, applications and processes. It involves managing complex data workflows, ensuring that data is collected, processed and delivered where it’s needed with minimal manual intervention. Orchestration tools enable businesses to integrate data from disparate sources, schedule tasks, handle dependencies, manage resources and gain observability over the end-to-end data journey.
The goal is to make data available in the right format, at the right time and in the right place while ensuring efficiency and scalability. Data orchestration plays a critical role in enabling real-time analytics, decision-making and data-driven operations, often utilizing cloud services like AWS or container orchestration with Kubernetes.
What are the main 3 stages in the data pipeline?
The main three stages in a data pipeline are:
1. Data extraction: This is the initial stage where data is gathered from various sources, which can include databases, APIs, IoT devices or external applications. The extraction process often involves pulling data from structured, semi-structured or unstructured formats, ensuring the raw data is ready for the next steps.
2. Data transformation: In this stage, the extracted data is cleaned, formatted and transformed to fit the needs of the destination system. This may involve tasks such as data normalization, filtering, aggregation or applying business rules. Transformation ensures that the data is in a usable format and consistent with the requirements of the target system, such as a data warehouse or an analytics platform.
3. Data loading: The final stage involves loading the transformed data into a target system, such as a data warehouse, database or a cloud storage platform. This is where the data becomes accessible for analysis, reporting or business intelligence applications. Depending on the use case, loading can occur in batches (bulk loading) or in real-time (streaming).
Learn more about the complexities of data management and how blockages in your data pipelines can affect the quality of data sources.
Solutions
Company

© 2026 All Rights Reserved