
Enterprise-grade orchestration simplified
RunMyJobs simplifies data pipeline integration across heterogeneous hybrid environments from platforms like Snowflake, Informatica and dbt Labs to hyperscaler services like Azure Data Factory and AWS Glue, BI tools like Tableau and PowerBI and AI platforms like ChatGPT and Palantir Data Foundry.
-

Operationalize AI with production-grade data
Scale AI from pilot to production with governed data workflows in real time to batch process orchestration across hybrid systems.
-

Reliable data delivery across hybrid environments
Ensure data arrives complete, current and on time across cloud, on-premises and ERP system dependencies.
-

Event-driven and batch workflow coordination
Coordinate event triggers with scheduled workflows to support both instant response and core system dependencies.
-

Reusable templates
Easily integrate Airflow and other data pipelines into business service workflows with scalable, reusable workflow templates and connectors.
-

Agentless SaaS architecture
Eliminate expensive legacy self-hosted schedulers and the unnecessary cost of server and database infrastructure, agent maintenance and upgrade cycle toil.
-

Audit-ready workflow execution
Generate audit-ready records automatically with workflow history, access controls and dependency tracking built into every execution.
A unified data + application orchestration platform for enterprise processes
Enterprise orchestration requires more than job scheduling; it is integral to DevOps and DataOps processes. RunMyJobs provides end-to-end workflow control across cloud-based systems, data warehouses, ERP and core applications with governance that helps developer and data teams streamline data delivery into production business application services across your hybrid environment.
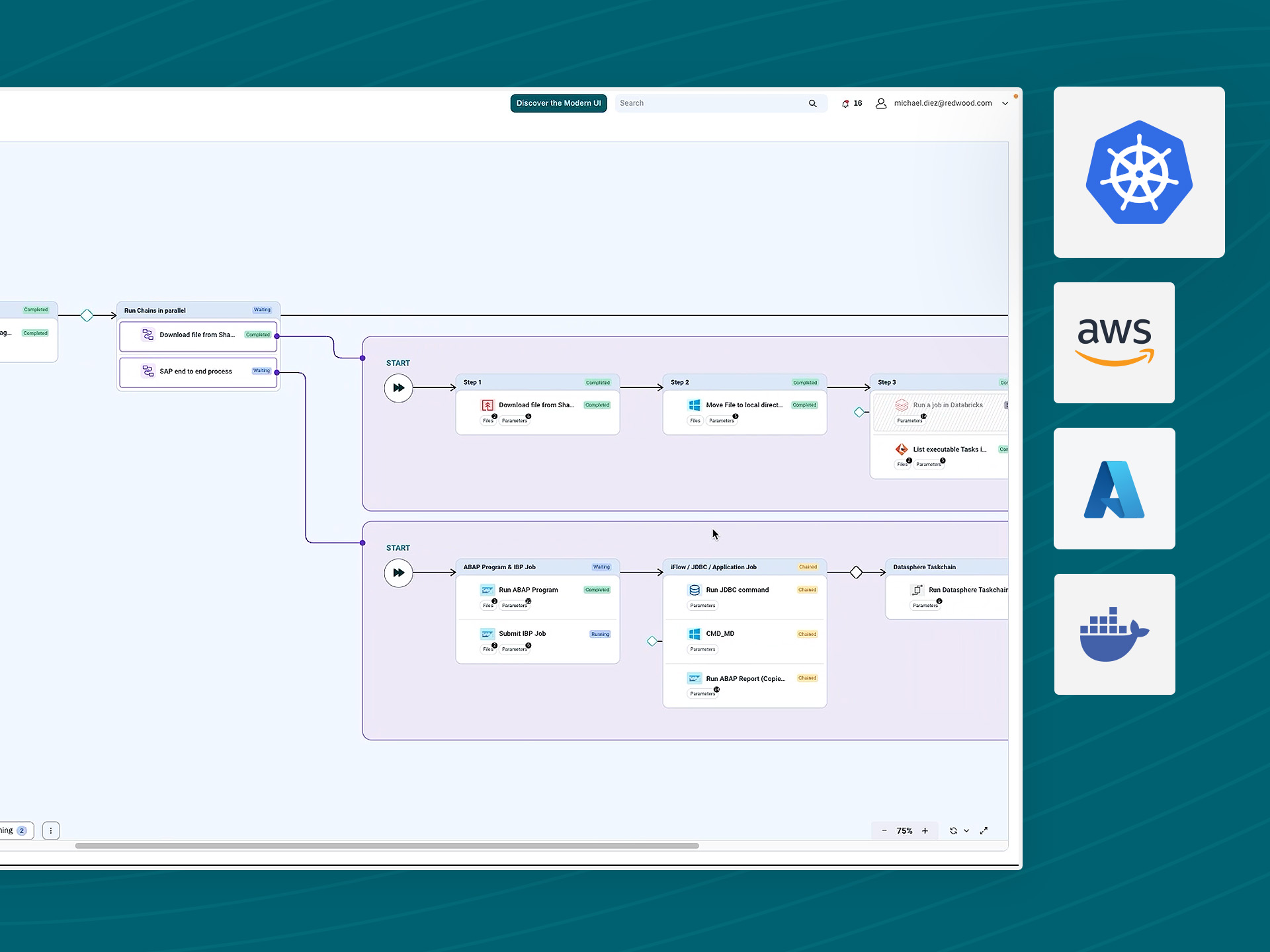
- Accelerate application and data pipeline integration with reusable workflow templates and connectors
- Connect data tooling silos with pre-built connectors and low-code integrations
- Debug application and pipeline workflow bottlenecks with troubleshooting dashboards and root cause analysis
- Optimize complex application and data workflows with real-time metrics and quality checks
- Process data volumes across serverless, Kubernetes and hybrid workloads to match enterprise computing requirements
Pipeline orchestration built for production, not just scheduling
Most data platform tools offer basic job execution capabilities. RunMyJobs focuses on business outcomes. Orchestrate complex business service workflows with SLA management, governance and observability that enterprise-class production requires.
- Bring open-source schedulers under unified enterprise governance and SLA controls
- Enable on-demand processing with modular, reusable workflow components
- Monitor data volumes and metadata with real-time dashboards and metrics
- Optimize runtime performance with declarative scheduling and version control
- Streamline data moves from raw data sources to business intelligence systems
When data workflows break at the handoffs
Enterprise data workflows mainly fail at the handoffs between systems, not on individual jobs. Fragmented orchestration tooling creates dependency fog, missed SLAs and expensive manual recovery efforts when there is no unified control plane to integrate and orchestrate the interdependent workflows.
-

AI and analytics ROI dies on stale data
AI models and analytics programs lose accuracy and trust when data arrives late or incomplete. Executives defending AI investments cannot answer whether the data was delivered completely and on time with confidence.
-
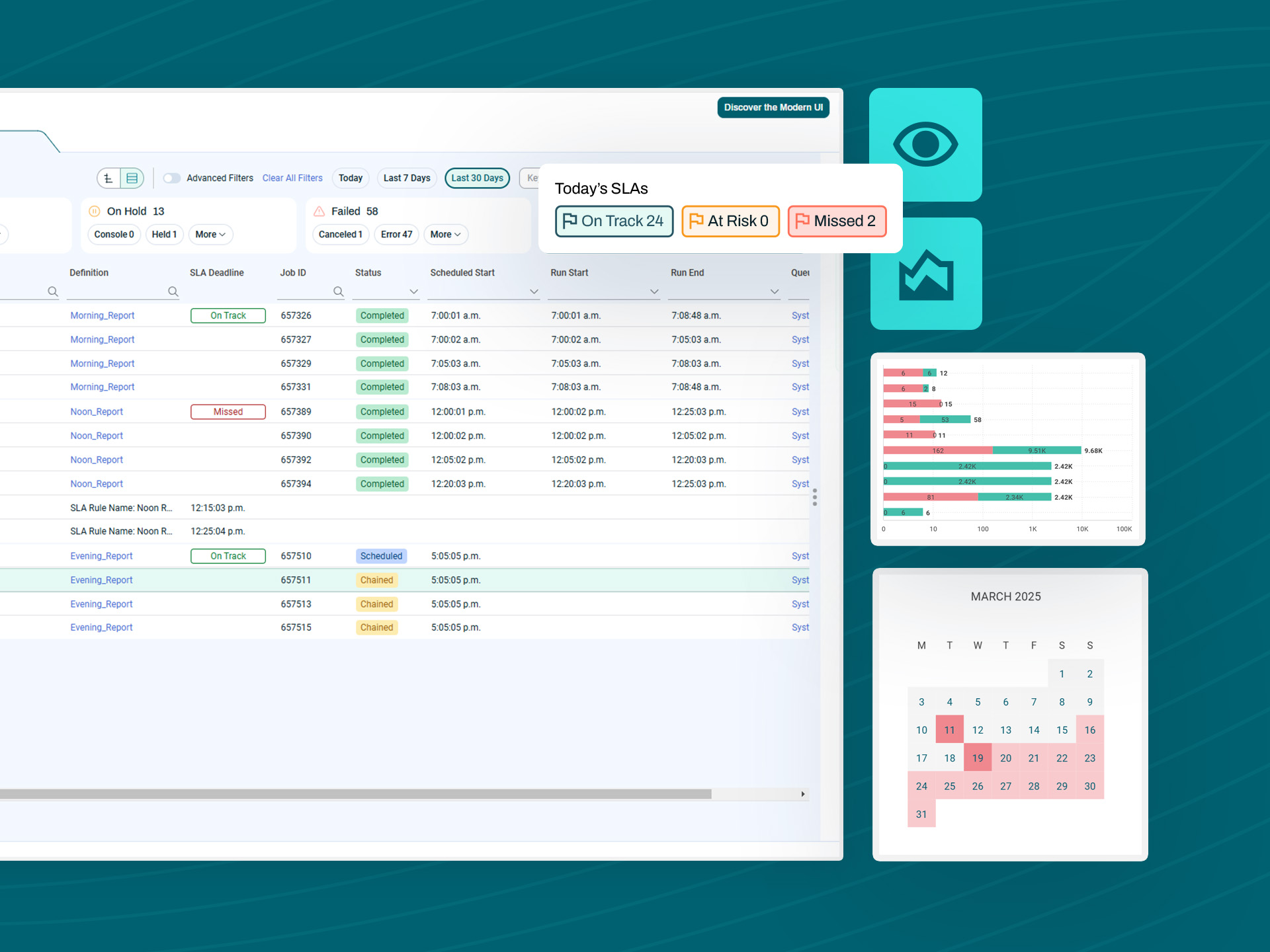
Green statuses hide business delays
Technical job success does not equal business SLA attainment. Data workflows can show green completion status even when arriving hours late, creating accountability gaps between IT monitoring and business deadlines.
-
Fragmented machine learning workflows
ML model refresh, retraining and downstream execution lack end-to-end coordination. Production AI workflows fail when data dependencies are hidden, and model performance degrades due to inconsistent data feeds.
-
Bespoke pipeline factories create backlogs
Every business unit data request becomes a custom pipeline build with unique maintenance requirements. IT teams cannot scale data delivery when each workflow is rebuilt from scratch for different domains that don’t connect.
Supporting capabilities for enterprise data operations
RunMyJobs extends beyond data orchestration to provide a complete enterprise automation foundation. Integrate complex data workflows within business applications and gain built-in governance and operational monitoring and control to streamline workloads across your technology stack.
-
Predictive SLA monitoring
Manage SLA TimelinesMonitor data workflows against business deadlines with predictive alerts and automated recovery capabilities.
-
ERP + SaaS integration
Unify Your PlatformsConnect data pipelines to ERP and cloud platforms through native connectors that preserve clean-core principles.
-
Event-driven automation
Use Events and TriggersTrigger data workflows from real-time events while coordinating with batch schedules and legacy system dependencies.
-

Governed compliance
Generate compliance evidence automatically with workflow lineage tracking, access controls and operational reporting.
-

AI/ML performance
Orchestrate data refresh, model retraining and downstream execution with governance controls for enterprise production AI workflows.
-

Data pipeline management
Automate end-to-end data processing with dependency visibility, error handling and recovery across hybrid environments.
Connect orchestration workflows across your technology stack
RunMyJobs provides pre-built connectors for open-source data schedulers, data warehouses, cloud-based services and business intelligence systems. Deploy integrations quickly with low-code tools while maintaining governance, compatibility and observability across your data ecosystem.
Master enterprise data orchestration
Learn more about data pipeline and application workflow orchestration, enterprise governance through expert analysis, customer stories and practical guidance for modern data operations.



Data orchestration tools FAQs
What is data orchestration?
Data orchestration is the automated coordination and management of complex workflows across multiple systems, applications and data environments. It involves scheduling, monitoring and governing data pipelines, ETL processes, data integration, data transformation and data moves to ensure the right data flows reliably from raw sources through processing steps to data warehouses and business intelligence systems.
Data orchestration platforms provide workflow management capabilities that handle complex data dependencies, retries, error handling, debugging and observability for end-to-end data processing. This includes coordinating batch processing, serverless functions and real-time data flows across cloud-based platforms, Kubernetes environments, on-premises infrastructure and hybrid ecosystems while maintaining data quality, governance, metadata management and SLA compliance. Modern orchestration tools optimize data volumes, streamline integration capabilities and provide dashboards for monitoring metrics, quality checks and troubleshooting bottlenecks throughout the data lifecycle with declarative, low-code approaches that support SQL, dbt, Databricks and open-source schedulers.
RunMyJobs by Redwood provides enterprise data orchestration across SAP, cloud platforms and legacy systems with agentless architecture. Orchestrate data workflows with predictive SLA monitoring, automated remediation and governance that connects data pipelines to business execution.
What is the difference between data orchestration and data pipeline management?
Data pipeline management typically focuses on individual ETL or ELT workflows within specific data engineering contexts, often using open-source tools to manage directed acyclic graphs (DAGs) and Python-based data processing tasks with version control and versioning capabilities. Data orchestration encompasses broader workflow management that connects data pipelines with business applications, enterprise systems and data-driven operational processes.
While data pipeline tools excel at managing datasets, data transformation and machine learning workflows within siloed data teams using SQL and dbt functions, orchestration platforms provide enterprise-grade capabilities, including SLA management, cross-system dependencies, event-driven automation, data governance controls and integration with ERP systems, cloud-based services, serverless infrastructure and legacy systems. Data orchestration platforms bridge the gap between isolated data engineering workflows and mission-critical business execution, offering ease of use through low-code interfaces, comprehensive metadata tracking, real-time metrics and notifications for stakeholders across complex data environments.
RunMyJobs by Redwood bridges data engineering tools with enterprise business workflows. As the only SAP Endorsed App in its category, it orchestrates data pipelines alongside ERP processes, providing the governance and observability required for production data delivery.
Why is data orchestration important for AI operations?
AI and machine learning models require fresh, high-quality data assets to maintain accuracy and deliver reliable business outcomes across data-driven decision processes. Data orchestration ensures ML workflows have access to current datasets through automated data refresh, model retraining coordination, real-time data integration and orchestration processes that optimize data volumes and streamline complex data flows.
Without proper orchestration, AI initiatives suffer from stale raw data that degrades model performance, inconsistent data feeds that break machine learning pipelines and a lack of data governance around AI data lineage, metadata management and decision-making processes. Orchestration platforms provide the scalability, observability, debugging capabilities and workflow management functions needed to move AI from experimental use cases to production-grade operations with automated quality checks, dependency tracking, troubleshooting dashboards, root cause analysis and integration with enterprise APIs, business intelligence systems and data warehouse environments across serverless, Kubernetes and cloud-based infrastructure.
RunMyJobs by Redwood orchestrates AI workflows from data refresh through model retraining to downstream execution with governance controls. Ensure machine learning models operate on current data with automated recovery, dependency tracking and audit trails for production AI.